概括
Wide & Deep模型是Google于2016年在DLRS上发布的推荐系统模型(论文链接)。它的主要思想是同时兼顾模型的记忆性(Memorization)和泛化性* (Generlization)。论文用Wide模型来负责记忆部分,用来负责学习和预测特征之间的相关性;同时,用Deep模型来负责泛化部分,发现历史数据中较少出现的新的特征组合。在模型的选取上,作者用一般的线性模型作为Wide模型,用DNN作为Deep模型。通过同步训练Wide模型和Deep模型,来同时达到对用户历史行为的归纳和对新的物品种类的推荐。
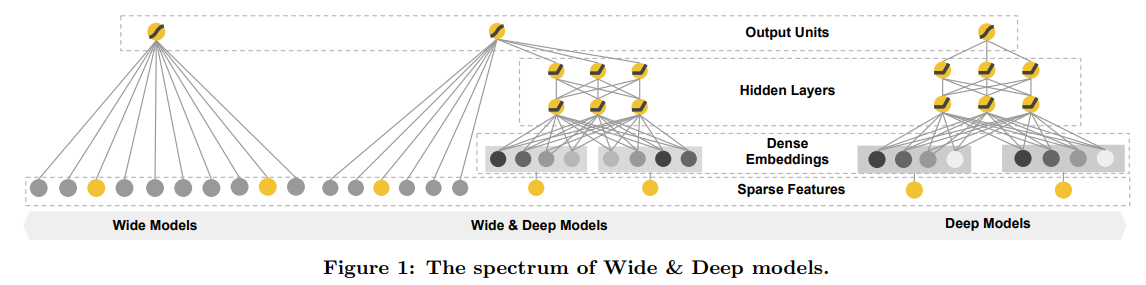
模型原理
- Wide模型
Wide模型是一个广义线性模型(generalized linear model),具有$y=\omega^Tx+b$ 的形式。模型的特征有原始输入特征和处理特征(transformed features),作者特别强调的一种处理特征是外积变换特征,例如一个外积变换特征”AND(gender=female, language=en)”,只有在同时满足”gender=female”和”language=en”的时候取值为1,其余情况取值为0.
- Deep模型
Deep模型是一个前馈神经网络模型,隐藏层之间的传播的逻辑是$a^{(l+1)} = f(W^{l}a^{l} + b^{l} )$。在输入到DNN网络以前,需要对输入的特征通过Embedding层降维到$O(10)-O(100)$之间。Embedding层原始权重随机,和最终的损失函数同步训练。
- Wide & Deep 模型同步
Wide模型和Deep模型是通过它们的对数几率权重的加和完成的。需要注意的是两个模型并不是分别训练加和的,而是在训练的过程中,损失函数就已经通过加权的方式求和,因此,Wide和Deep模型是协同训练的。这种协同训练的方法要求Wide模型的主要功能是对Deep模型记忆性不足做补充,而不是训练一个全新的全尺寸(full size)的线性模型,因此Wide模型的特征选取专注于少量外积特征,而不是所有特征。
- 模型结构
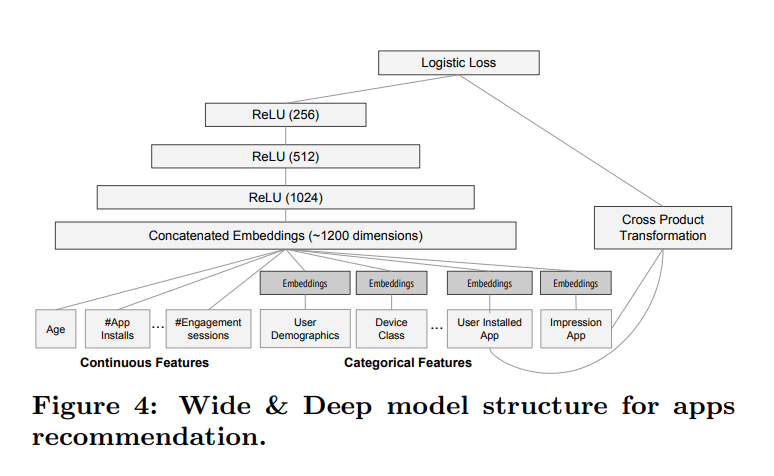
Wide & Deep模型的结构如上图所示。Wide模型中,一些明显的模型通过外积的形式输入到模型里,作为损失函数的一部分。而Deep负责深层次的挖掘特征组合,因此,Embedding层非常有必要在Deep层中引入,论文中采用了32层输出的Embedding层对大量稀疏特征做了稠密化处理。最后,论文中对稠密化处理的所有特征和连续特征,归并成1200维的特征再经过三层ReLU层,和Wide模型的输出共同组成了整个模型的损失函数。
一些总结
Wide & Deep模型最主要的先进思想总结起来有三个:记忆,泛化和交互特征。记忆帮助模型学习已有的特征组合,这些特征一般都是历史出现的,或者是人觉得显而易见的(也可以成为可解释的特征),因此这一部分的模型需要。而泛化,更多的是挖掘一些深入的,不显著的特征。这类特征的维度一般很大,因此Embedding的技术引进会非常有必要。而交互特征,是为了弥补单个类别特征预测效果差而引入的,传统的FM方法,是二维特征的直接交互。而Wide & Deep模型中,是Embeddeding后的特征做外积交叉,模型学习到的更多是高维特征的交互,对模型的预测效果会更加有效。